
DEAP-FAKED: Knowledge Graph based Approach for Fake News Detection
Authors: Shakshi Sharma (University of Tartu, Estonia); Rajesh Sharma (University of Tartu, Estonia)
Fake News on social media platforms has received a lot of attention in recent years, notably for incidents relating to politics (the 2016 US Presidential election) and healthcare (the COVID-19 infodemic, to name a few). Several approaches for identifying fake news have been presented in the literature. The methodologies range from network analysis techniques to Natural Language Processing (NLP) and the use of Graph Neural Networks (GNNs).
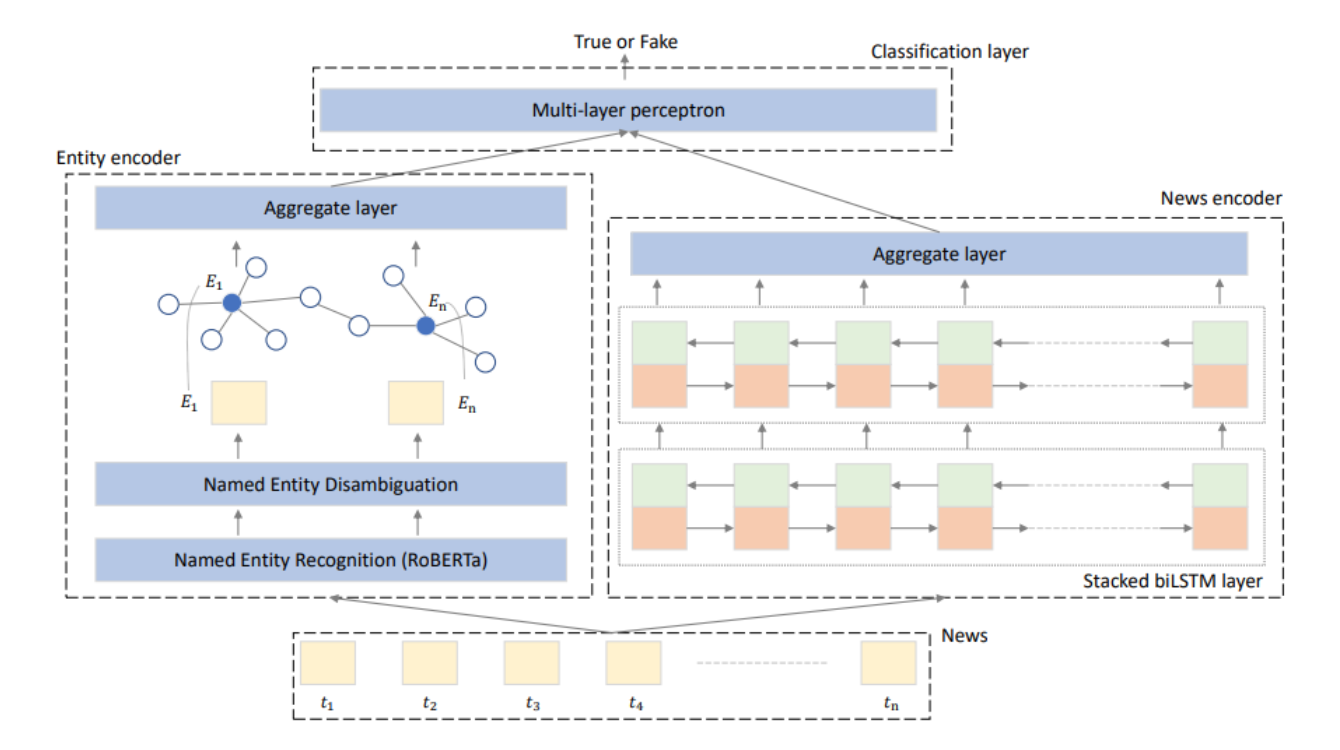
In this work, we developed a framework called DEAP-FAKED (a knowleDgE grAPh FAKe nEws Detection) for detecting Fake News. Our method combines Natural Language Processing (NLP), where we encode the news content, and the Graph Neural Networks (GNN), where we encode the Knowledge Graph (KG) techniques. The diversity of these encodings gives our detector an additional benefit. The framework is comprised of two parts. In the first part, we use an NLP-based approach to encode the news content. We utilize the news title in our case. We employ biLSTM-based neural networks for this, which are the de facto method of encoding sequence data. We locate and extract named entities from the news text in the second part, then map them to a KG. The entities in the KG are then encoded using a GNN-based approach. To identify Fake News, these two parts are then concatenated together.
This proposed framework employs little text, i.e., simply the headlines of the news stories, which saves time and replicates the low-text Fake News distribution seen on social media platforms. In addition to the low-text news headline, we recognize named entities and map them to an open-source KG. Following an unsupervised KG embedding approach, embeddings are trained for entities in the KG, and the representation of the relevant entities is then filtered out for Fake News classification. On the dataset side, we take into account a wide range of datasets from various disciplines.
We tested our methodology against two publicly available datasets that comprise articles from a variety of fields, including politics, business, technology, and healthcare. We also eliminate bias, such as the source of the articles, as part of the dataset pre-processing, which might affect the models' performance. DEAP-FAKED achieves an F1-score of 88% and 78% for the two datasets, respectively, an improvement of ∼21% and ∼3%, demonstrating the efficiency of DEAP-FAKED.