

Computational methods for the analysis of online hate speech against refugees and migrants - Part 1 -
Exploratory: Migration Studies
Online hate speech deserves special academic attention because of its social implications, as it can be an important predictor of hate crimes towards vulnerable individuals or groups. In Europe, it has not stopped rising in recent years, while these types of crimes are also increasing. Müller & Schwarz, (2018) explain that there is a correlation between hate speech online and hate crimes, so it is essential to study these types of messages that are transmitted on social networks in order to prevent and counteract their effects.
The social media that stands out for fostering debate and opinion, but also, and for that very reason, for being one that generates and spreads the largest amount of hate speech today, is Twitter. In this social network, messages with hate speech towards diverse vulnerable groups have continued to increase, both by common users, but also by famous people and with a large number of followers, as well as by profiles of political parties, groups and associations. Even during the recent health crisis, hate speech on Twitter has also increased, directed this time towards politicians, but also towards patients and those infected by Covid-19.
Without a doubt, one of the stigmatized groups that is historically the victim of a greater amount of hate crimes is that of migrants and refugees. And among the main reasons for this type of hatred is racism and xenophobia, feelings of rejection that have also increased in recent years, especially since 2015, with the worsening of the migration crisis in Europe and the Mediterranean. This situation, in addition, has been accompanied by the rise of ultra-right parties in Europe, and the increase in rejection speeches by the media and institutions, as well as by the growth of anti-immigration policies in many countries of the continent.
The STOP-HATE Project
With this premise, the Observatory for Audiovisual Contents of the University of Salamanca develops the project Development and evaluation of an online hate speech detector in Spanish (STOP-HATE), funded by the General Foundation of the University of Salamanca and the TCUE Plan [2018-2020]. The main objective of this project is to develop an online hate speech detector using big data techniques and supervised machine learning. For this, in this project the University of Salamanca has the support of the Cloud Computing service of SCAYLE (Castile and León Supercomputing Centre), to monitor hate messages on Twitter in Spanish on a large scale.
STOP-HATE is developed with the purpose of automatically detecting hate messages on Twitter in Spanish for reasons of racism/xenophobia, sexual orientation, religious beliefs, and political ideology. However, the attention has focused on hate speech for racist/xenophobic reasons, since, as indicated above, displaced and foreign people is one of the stigmatized groups that currently generates the most rejection in European public opinion. Secondarily, thanks to the work carried out, the final aim is to acquire empirical knowledge about what types of hate messages are transmitted on the internet, about what kind of sources or people profiles spread more frequently hate speech on social media as Twitter, what are the types of vulnerable groups and, specifically, the types of migrants and refugees that are victims of more hate speech on Twitter, and how those messages ultimately relate to hate crimes.
Previous studies of hate speech towards migrants and refugees on Twitter in Spanish
To carry out the STOP-HATE project, several preliminary manual analysis of hate messages in Spanish spread through Twitter were previously developed. These exploratory studies served to build a database of hate messages, as well as a prior knowledge framework that would later allow the generation of machine learning models to carry out these analysis in an automated way.
Finally, the first massive and automated study to detect hate speech into tweets in Spanish was carried out, in which 337,116 messages published between July 19th and 29th, 2019 were downloaded. In this case, the collected tweets were classified using a previously trained model with the sample extracted from the manual analysis of the study carried out from April to May 2018. A total of 187,305 tweets were finally classified with a confidence level greater than 80%.
With this preliminary research, which would serve as a pilot study for the STOP-HATE project, it was intended to develop a first automatic detection model of hate tweets towards migrants and refugees, which would allow us to know what is the volume of rejection of this group on Twitter in Spanish, already using large samples. The percentage of hate speech in this work was 9.19% of the messages in which displaced people were mentioned. Below are the algorithms that were used to generate the model and their Accuracy, Precision, Recall, and F-score indicators, all of them acceptable.
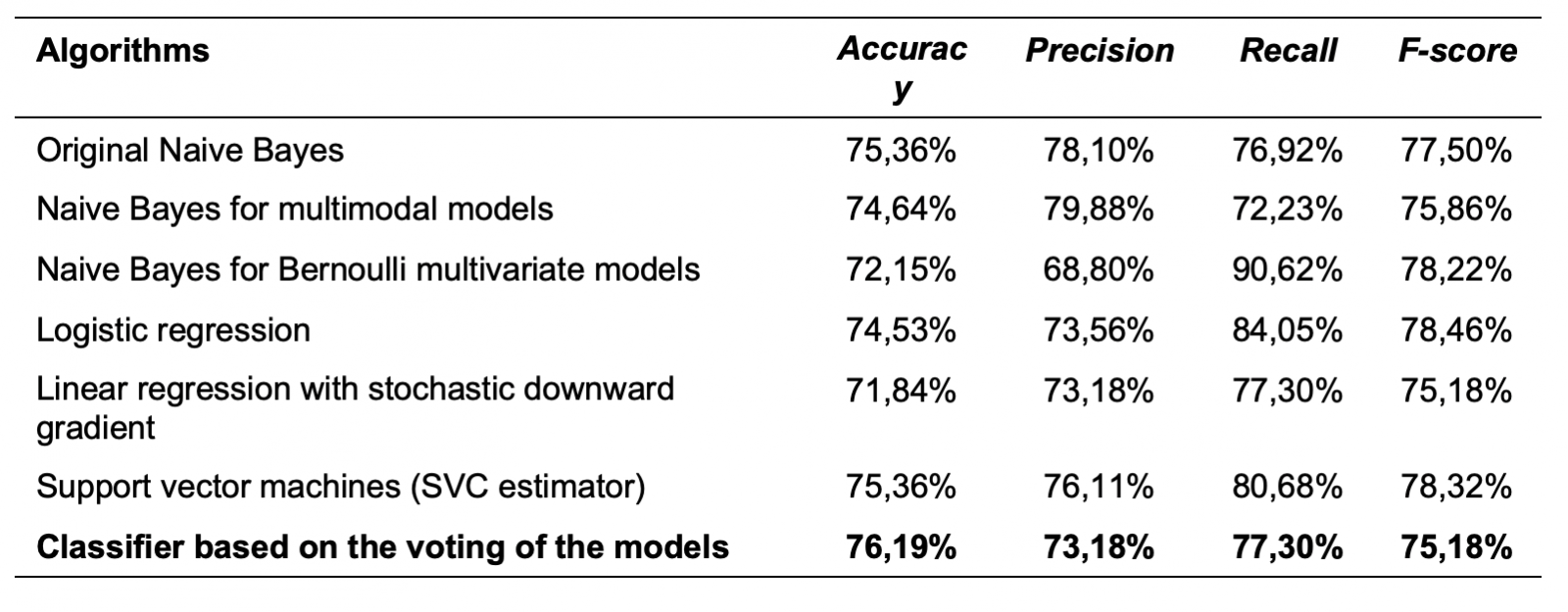
Accuracy, Precision, Recall, and F-score indicators of the algorithms
Developing an automatic hate speech detector on Twitter in Spanish
To develop the automated online hate speech detector in Spanish, the first step was to define the concept of hate speech to be detected, considering all the meanings and definitions up to now, as well as the European legal framework.
First, to be considered hate speech, the discriminatory message must be addressed to one of the vulnerable groups typified in the European framework (e.g., Jews, Muslims, Gypsies, LGBTI collective). In this sense, the types of prejudice or reasons of hatred towards these audiences are usually classified into eight categories:
- Racism/xenophobia;
- Sexual orientation or identity;
- Religious beliefs or practices;
- Political Ideology;
- Disability;
- Gender reasons;
- Antisemitism;
- Aporophobia.
In the STOP-HATE project we focus on the first four categories, paying special attention on detecting hate speech motivated by racist and/or xenophobic reasons, which is also what we focus on in this article.
On the other hand, according to the European Commission against Racism and Intolerance (ECRI General Recommendation nº 15, 2016), there would be a type of legal online speech which expresses rejection and intolerance, and an illegal hate speech, which could be considered a hate crime. The first is understood within the right to freedom of expression. Slight insults, criticism and offenses to individual or collective sensitivity would enter this type of speech. In some cases, it could be an attack on the dignity of the person, but not a hate crime.
Regarding speech as a hate crime, within this type of messages would be all those that directly or indirectly incite violence, intimidation, hostility or discrimination against a vulnerable group or an individual belonging to a vulnerable group (in this case migrants, refugees, asylum seekers and all kinds of vulnerable and stigmatized races, ethnicities and nationalities), and which take place in a public and mass context. In addition, as a theoretical approximation to the term, according to Calvert (1997), hate speech involves all the elements of communication transmission models (source, message, channel and receiver), which means that any strategy to understand and combat this type of hate must use a communicational approach.
Keeping this in mind, to develop the hate-speech detecting tool in STOP-HATE we use supervised machine learning and natural language processing techniques that involve communication approaches. In addition, given the difficulty in finding messages with illegal hate speech in Twitter within the European framework, we finally trained the model to detect all types of hate: legal and illegal, explicit or implicit, direct or subtle.
Secondly, once defined the type of hate speech we were to detect and use to train the models, Twitter accounts and labels were identified through which a greater amount of hate speech is transmitted in Spain, in order to collect examples of such messages. The messages were localized by generic keywords in which some of the predefined vulnerable groups were mentioned in some way. These messages were subsequently manually classified according to whether they only referred to the vulnerable public or whether they referred to the vulnerable public and included hate speech. After this, and basing on these early examples of messages with hate speech extracted from potential sources, a final selection of search terms was executed following also the distinction made by Kalampokis, Tambouris and Tarabanis (2013).[1]
In this sense, we created a list of words, stems, or combinations of those with rules, that mainly express hate motivated by the predefined reasons, and specially by racist or xenophobic reasons. This dictionary of hateful indicator words towards a specific collective was used as a filter to download tweets for a preliminary manual classification, that would serve later, in turn, to train the models. So, we recollected all the Spanish words or expressions that express hate towards displaced people by themselves, or accompanied by other words in any sentence. It is understood that the victims of this detected hate speech may be immigrants, refugees and asylum seekers but also, in specific, Asian, Arab, Latin American, or Sub-Saharan people or groups.
Once the filters were established, they were passed to code in order to download the necessary tweets from the Twitter API and using computational methods, to later generate the training corpus. Pre-set words and word combinations were used in this way as keywords to download the filtered tweets.

Example of the filter code to download tweets that can express hate for racist and xenophobic reasons in Spanish
After this, all the downloaded tweets were collected and compiled in a database for their subsequent manual classification. In the case of hate speech against refugees and migrants, a total of 24,000 filtered tweets were collected to be classified following the notions of a manual content analysis.
This manual classification was made, using the Doccano platform, by a primary coder, member of the project team, and eight trained secondary coders, people outside the project. In this way, the sample of filtered tweets was manually classified as hate or no-hate, discarding those tweets that were from other contexts or languages, or that contained vocabulary that may contaminate the model.
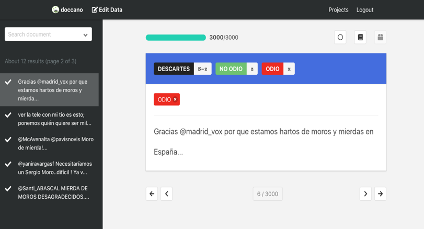
Example of tweets annotation with labelling on Doccano platform
Once all the tweets were classified by at least 2 people (the primary and the secondary coder), the results were crossed to finally collect only the reliable tweets, that is, those in which both coders agreed, which were classified with the same label by both of them. In this phase, the resulting corpus was cleaned, discarding tweets without agreement, so as not to contaminate the final training corpus.
Thus, from the initial sample of 24,000 tweets for the racism/xenophobia group, 11,643 were finally obtained with agreement, of which 3,751 were classified as hate and 7,892 were classified as no hate. 12,357 tweets were removed from the final corpus, adding the tweets discarded during the classification because they belonged to other contexts or were not relevant for the training set, and the unreliable or no-agreement tweets.
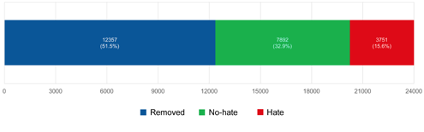
Final distribution of classified tweets about migrants and refugees to develop the training set
Having manually created this reliable corpus of hate speech messages, the last step was to use them to train and generate predictive models that would allow us detecting hate speech automatically. And this has been done by running binary classification algorithms as Logistic Regression, Naive Bayes, Support Vector Machines, Decision Trees and Random Forest. The Corpus was then used to provide these algorithms with the necessary examples so that, with that data, they can generate rules that provide us with predictive classification models with which to automatically detect whether or not new messages contain hate speech against refugees and migrants, in this case.
In a final phase of this project, which is currently running, we are moving from the mentioned shallow algorithms to deep learning algorithms in order to improve the large-scale forecasting models. Thus, the same training corpus manually generated, in this case, will be used to train Neural Network algorithms to generate more effective predictive models, for which the Scikit-learn, Keras and Tensorflow machine learning libraries are being used. In addition, this phase is being carried out with the technical support of SCAYLE, the Castile and León Supercomputing Centre, which make it possible to parallelize the process and thus improve computing capacity
The result of the project will be an online tool based on the intensive and parallel computation of data in a supercomputing infrastructure through which it will be possible to detect, verify, analyse and visualize online hate speech in Spanish against migrants and refugees, among other groups.
Written by: Carlos Arcila Calderón and Javier J. Amores, Observatory for Audiovisual Contents (OCA), University of Salamanca
Revised by: Matteo Bohm, Luca Pappalardo, Laura Pollacci